Product Page: https://ironpdf.com/python/blog/using-ironpdf-for-python/flatten-pdf-python-tutorial/
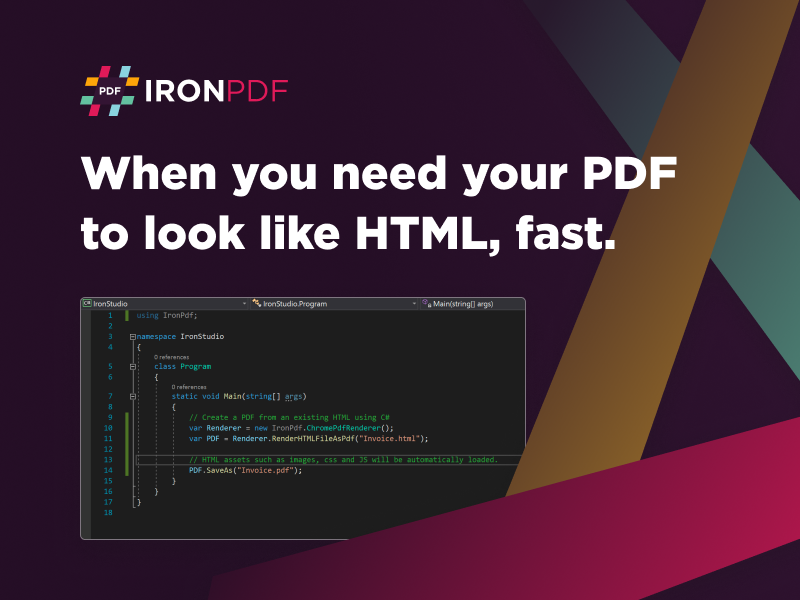
The Python PDF Library, a powerhouse in the domain of PDF manipulation, offers developers an extensive toolkit for effortlessly flattening PDFs. With its intuitive APIs and utilities, this library empowers developers to streamline the process of PDF flattening within their Python applications.

PDF flattening involves the conversion of interactive PDF elements, like form fields and annotations, into static content, effectively “flattening” them onto the document. This ensures that the document’s layout and content remain intact while eliminating any interactivity, making it suitable for various purposes such as archival, printing, or further processing.
By leveraging the Python PDF Library’s capabilities, developers can automate the PDF flattening process, saving time and effort. The library allows for the easy identification and processing of interactive PDF elements, enabling their flattening and seamless integration into the PDF document.
Additionally, the Python PDF Library offers developers the flexibility to control the flattening process, allowing for customization according to specific project requirements. Whether it’s flattening specific form fields, annotations, or entire pages, developers have the tools to tailor the flattening process to suit their needs.
To start incorporating PDF flattening into your Python workflow using the Python PDF Library, you can follow a comprehensive tutorial available https://ironpdf.com/python/blog/using-ironpdf-for-python/flatten-pdf-python-tutorial/. This tutorial provides step-by-step instructions, code examples, and best practices for effectively integrating the library into your applications. It equips you with the necessary knowledge to master PDF flattening in Python and enhance your document processing capabilities.
 <
<