Product Page: https://www.acdsee.com/en/products/photo-studio-ultimate
AI-Powered File Management and Photo Editing
ACDSee Photo Studio Ultimate 2024 is the complete solution for photographers and creatives of all levels. The software comes fully loaded with new and improved features boosted by timesaving, local Artificial Intelligence (AI) to help you organize, search, and edit your photos with minimal effort and maximum control.

Whats New in Photo Studio 2024?
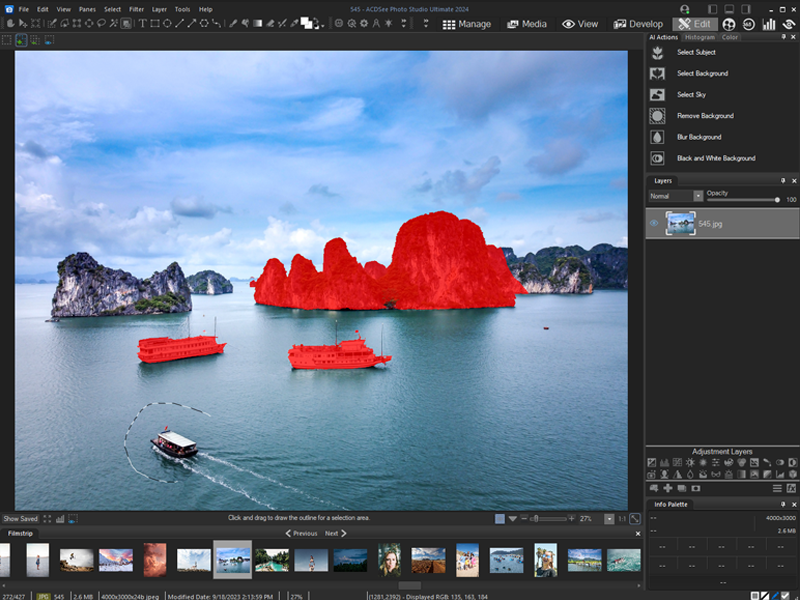
Accomplish more while doing less, with ACDSee Photo Studio Ultimate 2024. This years release is packed with new and improved Artificial Intelligence features to make your life easier. Use AI Keywords to search and find photos faster than ever, cutting out the tedium of manually assigning keywords, or hunting through thousands of photos for the perfect one. Making complicated selections on your images is now a one-click task with AI Select Subject, AI Select Background, and AI Select Sky added to Develop Mode. Use the new AI Sky Replacement to quickly create a stunning scene or sit back and let the new AI Object Selection Tool make intricate selections in Edit Mode. Portrait retouching has also been enriched with more control over eye direction and an added group of adjustments for skin in AI Face Edit. All this, plus overall performance improvements to Photo Studio Ultimates locally supported AI, make your photography workflow picture perfect.
Go Beyond the Horizon with AI Sky Replacement
The sky is no longer the limit with AI Sky Replacement. Easily define and replace the sky in any photo, resulting in a natural-looking composition thanks to foreground and reflection options for water. You can also use one of the many pre-installed skies, like Sunset, Storm, and Night Sky, to transform your wildest dreams into your horizon realities.
AI Keywords
Search and find photos faster than ever with zero-effort AI Keywords. Cut out the tedium of assigning keywords, or hunting for the perfect photo. Make finding your latest trip to the beach as simple as searching Beach.
 <
<