Product Page: https://ironpdf.com/blog/using-ironpdf/csharp-convert-pdf-to-text-tutorial/
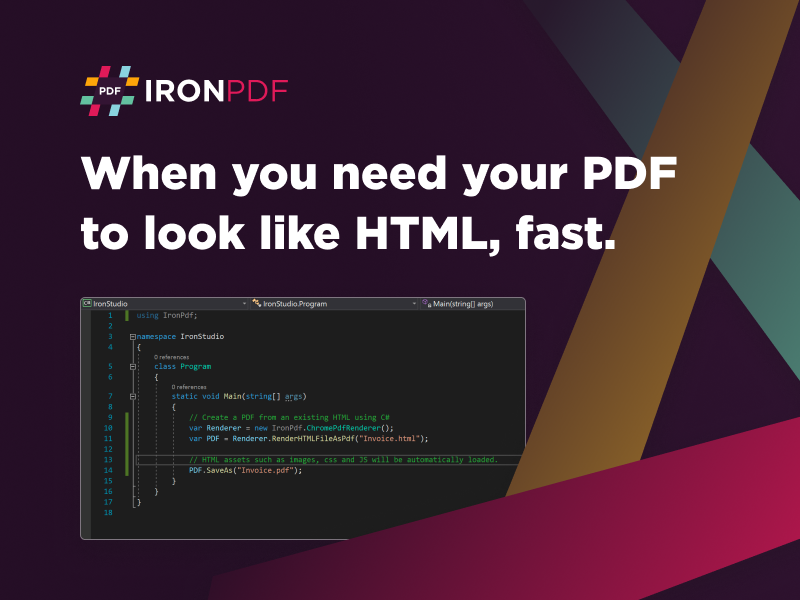
With this C# PDF library, converting PDF files to text is straightforward. The library offers methods that allow you to extract text content from PDF documents while preserving the formatting and structure. It handles various PDF formats, including encrypted and password-protected files, ensuring that you can convert a wide range of PDF files to text.
Additionally, the library provides options for customization and control over the conversion process. You can specify the pages or specific regions within the PDF document to extract text from, enabling targeted extraction of relevant information. Furthermore, it supports the extraction of metadata, such as author, title, and keywords, which can be useful for organizing and categorizing the extracted text.
Integrating the C# PDF library into your project is seamless, thanks to its user-friendly API and extensive documentation. The library offers detailed examples and guidance on how to leverage its features for PDF to text conversion, ensuring that developers of all levels can utilize it effectively. For tutorial and more information visit at https://ironpdf.com/blog/using-ironpdf/csharp-convert-pdf-to-text-tutorial/ .
Employing a C# PDF library for PDF to text conversion offers an efficient and reliable solution. With its comprehensive set of functionalities, support for various PDF formats, and customization options, it simplifies the process of extracting text content from PDF files. Whether you need to convert entire documents or extract specific sections, the C# PDF library provides the necessary tools to achieve accurate and efficient PDF to text conversion.